|
Обсуждение языковой трансляции
|
|
| DarkDemon | Дата: Четверг, 04.06.2026, 19:28 | Сообщение # 1 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Кто-нибудь писал языковые парсеры без общей теории на простых строковых функциях? Без выебонов: рекурсии
и сложных структур, просто в лоб.
Мне интересно послушать что скажут люди. Потом выскажусь сам. Пытаюсь оглядеться.
Сообщение отредактировал DarkDemon - Четверг, 04.06.2026, 19:28 |
| |
|
|
| DarkDemon | Дата: Понедельник, 08.06.2026, 01:21 | Сообщение # 2 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Ладно тема не хайповая, понимаю. Нужна затравка.
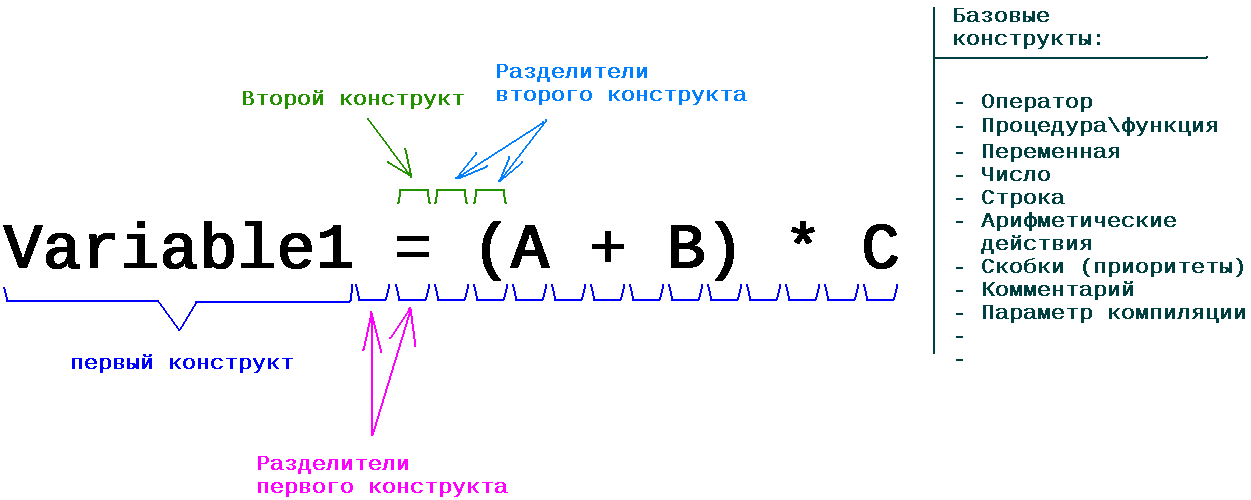
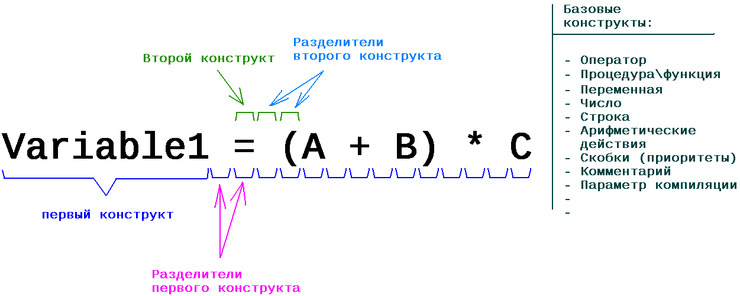
212 конструктов, т.е. операторов и ключевых слов старого BASIC, добавленных в следующую структуру
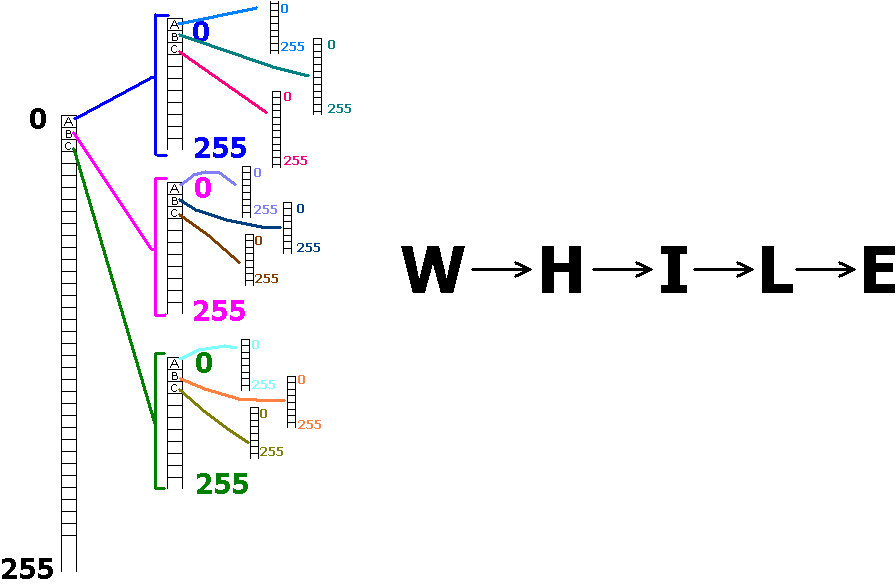
где каждый элемент это:
Код TYPE SyntTree FIELD = 1
pnext AS BYTE POINTER ' Поинтер на массив(память) из 256 букв
pprev AS BYTE POINTER ' Поинтер на предыдущий уровень, т.е. на массив(память) из 256 букв
id AS INTEGER ' Идентификатор конструкта
END TYPE
Занимают в памяти 3642 Килобайта или 3,55 Мегабайта.
Можно этого не делать и сравнивать строки в упор. Но будет сильно медленнее. Т.е. даже без выебонов,
всё равно требуется как минимум полноценное дерево, т.е. не заводя экономную структуру, а сразу по 256
элементов на каждую ветку. Даже так получается уже нифига не просто. Можно конечно подумать
как сэкономить, но не люблю выпендриваться там, где это по сути мало что даст. Не под DOS-ом же пишем.
Немного пробежался по этой теме. Конструкты называют токенами.
Общая теория не говорит как правильно постадийно в идеале должен проходить процесс, но люди пишут
про:
1) Лексер или токенайзер, т.е. преобразователь символов в токены(или как мне привычнее - конструкты)
2) Парсер, т.е. парсит конструкты и работает с лексемами
3) Стадия создания упрощённого кода (по 2 операции, например a = b + c, след строка d = a * e и т.д.)
4) Оптимизатор (оптимизирует т.н. упрощённый код)
5) Транслятор упрощённого кода в ассемблер
6) Линковка и генерация опкодов и бинарника.
Так вроде всё ровно, но есть недосказанность в первых двух стадиях. Никто не скрывает что там нет
100% точного подхода и по сути данная стадия является недетерминированным алгоритмом.
Сообщение отредактировал DarkDemon - Понедельник, 08.06.2026, 05:08 |
| |
|
|
| haav | Дата: Понедельник, 08.06.2026, 05:55 | Сообщение # 3 |
 Генералиссимус
Группа: Администраторы
Сообщений: 1478
Статус: Offline
| Может какие книги про создание компиляторов помогут? По идее там должны быть описаны подобные техники. Однако советовать никаких конкретных названий книг не буду , потому как я не в теме.
Вы сохраняете власть над людьми покуда оставляете им что-то…Отберите у человека все, и этот человек уже будет неподвластен вам…
|
| |
|
|
| DarkDemon | Дата: Понедельник, 08.06.2026, 07:56 | Сообщение # 4 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Стас, книги то помогут, дело не в этом, на самом деле там самые сложные этапы как раз последние(оптимизация
и генерация ASM кода), но не хочу готовыми решениями себе мозги забивать, они сильно сузят мышление.
Заметил, что когда не знаешь как сделано - можешь сделать по-другому, это влияет на общую архитектуру.
Дело в том, что перед тем как смотреть литературу и видосы по теме, первоначально сел чтобы немного помозговать
дабы сравнить опосля подходы, где использовать своё, а где уже известное.
И по итогу что-то сходится, а что-то наоборот. Например, не разграничиваю лексер и парсер. Большая часть
мне понятна, но там где-то слепое пятно(где-то в районе выражений по бейсиковским принципам, на уровне
проверки корректности в пачке со сравнениями + одновременным разбором лексем). Поэтому, чтобы понять
мол стоит ли туда вообще залезать с головой эта тема и создана.
Может кто чего крутил, напарывался, какие-то вещи народ знает важные. Уже лазил в недетерминиловку, оно
меня побеждает, а тут вроде бы жопочасы и +/- последовательный процесс, но не факт, важно понять насколько
не факт. Это как раз та задача, которую, если у проектного кодера спросить, за сколько он её сделает - то не скажет,
ну если прям откровенно. Тут уже не до передовых подходов и самоуверенности, сказать больше, по куче факторов,
сейчас каждое такое погружение может стать последним, а бывает оно ещё и оказывается не по плечу.
Короче почву прощупать. Если кто туда не лазил - то и не надо, это не агитация.
|
| |
|
|
| WQ | Дата: Среда, 10.06.2026, 18:33 | Сообщение # 5 |
|
Полковник
Группа: Проверенные
Сообщений: 217
Статус: Offline
| Цитата DarkDemon (  ) Кто-нибудь писал языковые парсеры без общей теории на простых строковых функциях? Без выебонов: рекурсиии сложных структур, просто в лоб.
Текст представляется в виде массива, потом посимвольно читается в цикле
|
| |
|
|
| DarkDemon | Дата: Четверг, 11.06.2026, 06:35 | Сообщение # 6 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| О, WQ, здарова! Тяжёлая артиллерия подъехала.
Кстати интересная мысль вместо того, чтобы постоянно дрючить строку через [], просто 1 лайн строки
загнать посимвольно в массив и там уже работать. Это прям хорошо.
Код пока не пишу, думаю над жизнью. Но мысли есть. Может конечно ошибаюсь, но пока есть довольно
устойчивое ощущение, что прям максимально простая распознавалка конструкций с самой общей базой
вполне может не превысить 1-1,5k кода. Но код плотный, не на расслабоне.
Верхний уровень алгоритмики: Задача - найти начало и конец конструкта, передать на верификацию.
Идём посимвольно, первый символ строки определяет возможный тип первого конструкта, но абсолютно точно
он определяет дальнейшие допустимые символы(либо текущего конструкта, либо уже следующего, либо раздел.).
Если это цифра - то в строке ошибка(мы не будем парсить номера строк), если буква - тогда либо оператор,
либо переменная. С цифры строка начинаться не может.
Если буква - значит либо переменная, либо оператор. Разделителями в таком случае являются либо знак равно,
(который будет означать что это выражение), либо скобки(параметры процедуры), либо конец строки.
Т.е. доходим до любого символа, который не цифра и не буква и проверяем на вышеозвученное, если
не является - значит ошибка, иначе делаем проверку на операторы(они нам известны) и вуаля - первый
конструкт мы знаем. Если это оператор - тогда действуем по логике операторов. Логику можно представить
как последовательность допустимых ID конструктов, на входе один конструкт - на выходе несколько допустимых
и тут допом ещё важна стадия в которой мы находимся, например если первый конструкт переменная,
второй - знак равно, а третий выражение, то после конструкта "выражение" больше ничего быть не может
и если там всё-таки что-то есть, значит в строке ошибка. Логика опять же шьётся в дерево, но уже с переменным
кол-вом отростков.
Всё что нам нужно знать - это делать разбор по 1-му конструкту и после каждого делать логические выводы
правильно или ошибка. (Как тов. Сталин говаривал: https://www.youtube.com/watch?v=pxrqirsC-Zo)
Думаю эта схема не подойдёт подо что-то сложное, но код плана QB скорее всего разложить на атомы получится.
Пока так. Идеи буду фиксировать в теме, чтобы не просрать.
|
| |
|
|
| WQ | Дата: Четверг, 11.06.2026, 19:06 | Сообщение # 7 |
|
Полковник
Группа: Проверенные
Сообщений: 217
Статус: Offline
| В лексере, который я пытался написать, основная задача - каждому символу присвоить номер (например, 0-256) стиля, чтобы потом при рисовании букв можно было использовать разные шрифты и цвета. Задача понять, о чем код, на тот момент не ставилась, хотя зная, где какие стили, дальше, возможно, это было сделать проще. Все это в рамках написания текстового редактора.
В простейшем случае весь код находится в некой последовательности номеров символов из Unicode, необязательно обычный массив, а может быть специальная структура данных\несколько структур.
В цикле каждый символ обрабатывается отдельно, чтобы понять, относится он к символам слов или разделителям - пробельным символам и символам окончания строки. Если текущий символ - символ слова, присоединяем его к временной строке, если разделитель - заканчиваем временную строку, сравниваем ее с ключевыми словами, определяем к какому типу ключевых слов относится найденное слово, и этим символам присваивается номер стиля. Если разделитель - символ окончания строки - помечаем где-то, что тут строка заканчивается. Цикл повторяется до конца текста. В некоторых случаях приходится "подсматривать" вперед на несколько символов, в других "оглядываться" назад.
Если текст небольшой, все это можно сделать на массивах, но если обрабатывать большие тексты, нужно все усложнять и оптимизировать.
|
| |
|
|
| DarkDemon | Дата: Пятница, 12.06.2026, 23:29 | Сообщение # 8 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Цитата Все это в рамках написания текстового редактора.
Тоже хотел редактор кода, но пока не идёт оно. Тупо условий нет. Устал бороться со всеми факторами.
Под ASCII (в основном под РФ). Задумок было много, все труднореализуемые(руками с нуля без библ) кроме хелперов,
полностью графический. Думал делать упор на коммьюнити, а сейчас со всем дерьмом, которое происходит у нас в IT -
считай бесполезняк, т.к. например, Radmin уже сдох, Hamachi сдох годом ранее. Короче уничтожают всё твари.
Так что не знаю. Кому это теперь будет надо. Сайты личные скоро, видимо, искоренят, везде будет ценз, спай и прессинг.
Так что парни, теперь лучше изучать защиту от отладки, устойчивые методы шифрования и думать как в этом
дерьме колупаться до конца своей жизни, достойной жизнью это назвать трудно, а вот термин колупание или "е*ля"
- хорошо подходит.
Цитата Если текущий символ - символ слова, присоединяем его к временной строке, если разделитель - заканчиваем
временную строку, сравниваем ее с ключевыми словами, определяем к какому типу ключевых слов относится
найденное слово, и этим символам присваивается номер стиля.
Да у меня так же будет. По другому не сделать.
Цитата Если текст небольшой, все это можно сделать на массивах, но если обрабатывать большие тексты, нужно все усложнять и оптимизировать.
Пока над этим не думаю. Просто бы какую н-ть элементарщину наваять. Просто не хочу делать как
увидел на ютубе. Например строковыми токенами, т.к. очевиден бинарный вид для скорости.
Конверсию такого вида можно для отладки сделать.
Пока встрял на втором дереве(лексемном). Не люблю эти структуры, много мозгов на них уходит.
|
| |
|
|
| zamabuvaraeu | Дата: Воскресенье, 28.06.2026, 12:37 | Сообщение # 9 |
|
Полковник
Группа: Друзья
Сообщений: 219
Статус: Offline
| Начинать можно с самого компилятора фрибесика.
Фрибесик компилируется тривиально: fbc -m fbc -g *.bas
Запускаем под отладчиком и смотрим: какие функции вызываются, как идёт исполнение кода.
|
| |
|
|
| DarkDemon | Дата: Воскресенье, 28.06.2026, 19:59 | Сообщение # 10 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Цитата zamabuvaraeu ( ) Запускаем под отладчиком и смотрим: какие функции вызываются, как идёт исполнение кода.
Да это понятно. Поначалу, конечно, надо самому попробовать. И уже потом сравнить разницу в генерации.
Но до этого ещё ой как далеко. Даже на уровне размышлений разбор кода - задачка аховая.
Короче пока дофига непоняток. Но и за компиль то сажусь дай бог раз в неделю.
Думаю как применить лексемное дерево и как вообще его скодить правильно в плане оптимизации.
|
| |
|
|
| zamabuvaraeu | Дата: Понедельник, 29.06.2026, 03:43 | Сообщение # 11 |
|
Полковник
Группа: Друзья
Сообщений: 219
Статус: Offline
| Сначала делаем лексический анализ.
Анализатор берет вводные данные в форме потока символов и распознаёт в них шаблоны, которые он режет на лексемы.
Код ' Тип лексемы (не все)
Enum TokenType
TokenInteger
TokenIdentifier
TokenString
TokenAs
TokenEqual
TokenPlus
TokenDim
TokenGreater
TokenLess
TokenLet
TokenIf
TokenThen
TokenElse
TokenEnd
End Enum
' Лексема
Type Token
Lexeme As String
tType As TokenType
End Type
Код Dim x As Integer = 100
Анализатор читает текст программы посимвольно, убирает мусор — лишние пробелы, табуляции, переводы строк, комментарии. И выдаёт массив лексем. Вот какие лексемы сгенерирует наш анализатор:
Код Dim ---> TokenDim
x ---> TokenIdentifier, Lexeme = "x"
As ---> TokenAs
Integer ---> TokenIdentifier
= ---> TokenEqual
100 ---> TokenInteger
Дальше на сцену выходит синтаксический анализатор, который из массива лексем строит Абстрактное Синтаксическое Дерево.Добавлено (29.06.2026, 04:00)
---------------------------------------------
Цитата Кстати интересная мысль вместо того, чтобы постоянно дрючить строку через [], просто 1 лайн строки
загнать посимвольно в массив и там уже работать. Это прям хорошо.
Тогда нельзя будет обработать операторы переноса и разбиения строк:
Код Dim x As _
Integer _
= 100
Dim x As Integer: If x = 0 Then Foo()
For i As Integer = 0 To 10: Print i : Next
|
| |
|
|
| zamabuvaraeu | Дата: Понедельник, 29.06.2026, 07:29 | Сообщение # 12 |
|
Полковник
Группа: Друзья
Сообщений: 219
Статус: Offline
| Вот так можно отлаживать FBC в студии:
|
| |
|
|
| DarkDemon | Дата: Вторник, 30.06.2026, 04:05 | Сообщение # 13 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Цитата Анализатор читает текст программы посимвольно, убирает мусор — лишние пробелы, табуляции, переводы строк, комментарии.
Не всё так просто. Знак комментария может быть внутри строки, чтобы понять что это не комментарий нужно делать разбор
посимвольно с самого начала. После каждого символа ситуация меняется и это ключевая фраза. Поэтому мусор так сразу
не уберёшь, его надо убирать в реалтайме, вместе с разбором фиксируя корректность всего что мы встречаем.
И вот как это сделать проще и пытаюсь понять. Пока не придумал.
AST - это общая теория, честно - не хочу её придерживаться, т.к. это всё слишком геморройно для моих старых мозгов.
|
| |
|
|
| zamabuvaraeu | Дата: Вторник, 30.06.2026, 07:23 | Сообщение # 14 |
|
Полковник
Группа: Друзья
Сообщений: 219
Статус: Offline
| Так и есть.
Лексический анализатор читает текст посимвольно, удаляет мусор и разбивает его на лексемы.
Синтаксический анализатор получает очищенный от мусора массив лексем и строит из него дерево.Добавлено (30.06.2026, 07:33)
---------------------------------------------
Чтобы спагетти‐кода не было: это два независимых процесса.
Нет никакого смысла нагружать лексический анализ тем, чем он заниматься не должен.
А синтаксический анализатор должен работать уже с готовыми лексемами, очищенными от мусора.
|
| |
|
|
| DarkDemon | Дата: Вторник, 30.06.2026, 14:01 | Сообщение # 15 |
|
Генерал-майор
Группа: Друзья
Сообщений: 345
Статус: Offline
| Цитата zamabuvaraeu ( ) Нет никакого смысла нагружать лексический анализ тем, чем он заниматься не должен.
Опять же не всё так просто. И над этим думаю.
Пример: IF выражение THEN
к.с слово THEN спарсится только после выражения, а выражение может быть некорректным, что должно останавливать парсинг,
но чтобы понять что мы сейчас парсим скажем не параметры функции в скобках, а именно выражение в скобках, нужно делать
разбор реал тайм. А выражение например может состоять из нескольких знаков равно, внутри него может быть функция ASC
со стоковым параметром, а внутри строкового параметра знак сука комментария... При этом на каждом символе оно ещё должно
понимать находимся ли мы в выражении или уже нет, потому как оно может встретить функцию внутри выражения, а может
встретить THEN, с точки зрения символов - это обе конструкции, состоящие из печатных ASCII символов интерпретирующиеся
идентично(именованное значение) и только после того как мы встречаем разделитель мы можем его опознать.
И это лишь одна конструкция.
Вот в чём сложность... Это СРАЗУ должна быть очень умная херня, чтобы разобрать такое. И чтобы она не начинала лопатить
некорректные части, потому что с большей долей вероятности это и приведёт к ошибкам в дальнейшем.
Рекурсивную писать не хочу. Думаю над итеративно контролируемым процессом. Хардкодить парсинг тоже не хочу, возможность
вносить коррекции на стадии разработки - нужна.
Добавлено (30.06.2026, 14:11)
---------------------------------------------
Цитата zamabuvaraeu ( ) Тогда нельзя будет обработать операторы переноса и разбиения строк
Оператор переноса я бы не стал вносить по многим причинам. Всегда был против этого оператора. Этим должна
заниматься IDE и есть много идей на счёт того, как сделать доступными визуально все параметры, вместо того чтобы
тратить вертикальное место экрана.
А вот оператор разбиения - нужен и его добавление сводится к отрезанию строки сразу в процессе его разбора,
что должно останавливать разбор сразу, это не так сложно реализовать при списочной структуре документа(двусвязный список строк).
Впрочем этот оператор при переизбытке тоже портит внешний вид кода, но к нему у меня вопросов меньше.
Ну и на самом деле пока не думаю как разбирать несколько строк. Там логика ещё сложнее. Одну бы строку разобрать для начала.Добавлено (30.06.2026, 14:40)
---------------------------------------------
Цитата Лексический анализатор читает текст посимвольно, удаляет мусор и разбивает его на лексемы.
Если у меня будет готовый массив конструктов, то мне никакие деревья уже будут не нужны.
Ну кроме заранее заготовленного и заполненного дерева известных лексем(последов. конструктов), просто чтобы
сравнить входное с тем что зашито.
Там возможно что-то потребуется такое, для разбора выч выражений(да и то не факт, алгоритмически думаю можно
обойтись), но об этом пока речи не идёт. Т.е. когда у нас уже будут помеченные символы начала и конца выражения,
что явл целым конструктом.
Цитата zamabuvaraeu ( ) Нет никакого смысла нагружать лексический анализ тем, чем он заниматься не должен.
Я решил попробовать разбор конструктов единым процессом. Во всяком случае пока.
CASE-ы не являются прямым спагетти кодом, если работают независимо. Спагетти это прыжки вместо подпрограмм и
это практически нельзя разбить в линейный вид. У меня линейный вид достигается итеративностью процесса.
Но здесь сложный многофакторный разбор, поэтому с точки зрения процесса - он уже сам по себе спагетти.Добавлено (30.06.2026, 14:44)
---------------------------------------------
Да и ещё по поводу хардкодинга. На 100% отвязаться - не получится. Это вроде бы должно быть понятно.
Т.е. документации о том, что хочется - надо много.
Сообщение отредактировал DarkDemon - Вторник, 30.06.2026, 14:14 |
| |
|
|
|